ᐅ Suprotec ТНВД отзывы — 1 честных отзыва покупателей о Присадки и промывки Suprotec ТНВД
Достоинства
Недостатки
Комментарий
Оценка
Принимаю условия предоставления данных.
- тип: присадка
- область применения: топливная система
- действие: увеличение мощности двигателя, снижение вибрации
Средний рейтинг Suprotec ТНВД – 4
Всего известно о 1 отзывах о Suprotec ТНВД
Ищете положительные и негативные отзывы о Suprotec ТНВД?
Из 11 источников мы собрали 1 отрицательных, негативных и положительных отзывов.
Мы покажем все достоинства и недостатки Suprotec ТНВД выявленные при использовании пользователями. Мы ничего не скрываем и размещаем все положительные и отрицательные честные отзывы покупателей о Suprotec ТНВД, а также предлагаем альтернативные товары аналоги. А стоит ли покупать – решение только за Вами!
Самые выгодные предложения по Suprotec ТНВД
Информация об отзывах обновлена на 01.01.2023
Написать отзыв
Чуня, 04.06.2020
Достоинства: На Хх давление в тнвд повысилось с 260 до 271.
Недостатки: На скорости больше 175 при езде больше 1-2 минут стало выскакивать ограничение мощности. Но возможно это связано с другой неисправностью
Комментарий: На ездовых и расходе особо не заметил разницу, но двигатель стал работать помягче. Кроме до этого залитой присадки AWS.
Кроме до этого залитой присадки AWS.
| Общие характеристики | |
| Тип | присадка |
| Область применения | топливная система |
| Действие | увеличение мощности двигателя, снижение вибрации |
| Способ применения | Обработка насоса высокого давления производится следующим образом: Тщательно перемешайте флакон с составом «ТНВД», так чтобы осадок на дне распределился по всему объему жидкости; Перед заправкой добавьте в топливный бак половину содержимого флакона (смотрите отметки на срезе этикетки). Точная дозировка состава осуществляется из расчета 1 мл состава на 1 литр топлива; Заправьте полный бак дизельным топливом. Сразу после добавления состава машиной можно пользоваться в режиме штатной эксплуатации. Через 2000-2500 километров процедуру необходимо повторить: Перемешайте остаток состава «ТНВД» во флаконе, чтобы распределить осадок по всему объему жидкости; Перед заправкой добавьте вторую половину флакона состава в топливный бак; Заправьте полный бак дизельным топливом. |
Производители
- LIQUI MOLY14
- Lavr9
- Hi-Gear3
- Suprotec3
- ASTROhim2
- Extratabs2
- XADO1
- RUTEC1
- ZIC1
- Golden Snail1
- ЛУКОЙЛ1
- StepUp1
- WYNN’S1
Показать еще
преимущества и последствия Чип-Тюнинга
Разберемся с определением «чип-тюнинг» – в превую очередь программное вмешательство в режим работы ECU с намерением улучшить различные стороны работы двигателя.
Рано или поздно, у владельца появляется желание улучшить автомобиль, это желание вполне естественно. Желание что-то изменять появляется не только к автомобилю, людям постоянно необходимо все улучшать в своей жизни — это психологический аспект жизни. Человек привыкает ко всему, так же он привыкает к автомобилю, после нескольких лет эксплуатации, все возможности автомобиля становятся обыденностью, вождение превращается в рутину. Пропадает чувство восторга от нового автомобиля после покупки, динамика и скорость автомобиля уже не удивляют, и вождение становится скучным и обыденным. Каждый может вспомнить момент, когда двигатель его любимца неожиданно начал троить, или мощность просто упала, а посещение станции техобслуживания все откладывалось. Но вспомните первые впечатления после ремонта — оказывается машина очень резвая, и тянет хорошо! Вот такие же эмоции возникают после чип-тюнинга.
Человек привыкает ко всему, так же он привыкает к автомобилю, после нескольких лет эксплуатации, все возможности автомобиля становятся обыденностью, вождение превращается в рутину. Пропадает чувство восторга от нового автомобиля после покупки, динамика и скорость автомобиля уже не удивляют, и вождение становится скучным и обыденным. Каждый может вспомнить момент, когда двигатель его любимца неожиданно начал троить, или мощность просто упала, а посещение станции техобслуживания все откладывалось. Но вспомните первые впечатления после ремонта — оказывается машина очень резвая, и тянет хорошо! Вот такие же эмоции возникают после чип-тюнинга.
Некоторые из читателей вполне могут вспомнить времена повальной популярности отечественного автопрома. В те времена, многие знали, что добавить «резвости» автомобилю можно выставив зажигание на позднее время. Для этого надо было лишь повернуть крышку трамблера на несколько градусов. Только этим способом в свое время спасались люди в горных местностях, это помогало вернуть автомобилю мощность при нехватке кислорода на высоте.
Увеличить мощность можно было перенастроив карбюратор автомобиля. Но такую операцию мог сделать не каждый, тем более, в работе необходим газоанализатор.
Именно такие способы корректировки работы двигателя стали прародителем для современного чип-тюнинга. Отличия лишь в том, что на современных автомобилях все параметры регулируются «электронными мозгами» в отличие от старых, где вся настройка происходила регулировкой физических элементов. На данный момент приходится вмешиваться в работу программной части ECU.
Чем опасны изменения микропрограммы?
Начнем с того, что чип-тюнинг — это самый быстрый, менее затратный и безопасный метод, подойдя к этому профессионально. Другие способы улучшения двигателя: замена распредвала, установка укороченных шатунов, изменение впускной и выпускной системы двигателя и т. д. – обойдутся автовладельцу в значительную сумму и придется затратить много времени на переборку двигателя, и все равно желательно сделать перенастройку ECU для стабильной работы силового агрегата.
Сейчас, мало владельцев автомобилей с тем или иным способом тюнингованными двигателями, поэтому человеку захотевшему улучшить свой автомобиль, приходится ориентироваться на информацию из ненадежных источников. В результате информационного дефицита рождаются сомнения, а они рожают много негативных отзывов и мнений. Такие статьи в основном исходят от «теоретиков» или любителей, подошедших к форсирования двигателей безответственно, в основном, каждая статья сводится к третьему закону механики — каждое действие равно противодействию. С этим утверждением не поспоришь, все авторы правы (в какой-то мере). Ошибаются только в одном, в размере противодействия при грамотном подходе к делу. Спорить с утверждением, что при повышенных нагрузках работы двигателя — и повышается износ ресурса работы мотора. Однако, стоит учитывать практическую часть проблемы — на сколько именно увеличится износ двигателя при чип-тюнинге.
Например, в статьях приводятся цифры от 10% до 30% уменьшения срока службы двигателя. Но существует единственный нюанс, ни в одной статье не приводится формула или методика подсчета увеличения износа. Стоит заметить, при профессиональном подходе к перепрошивке «мозгов», износ двигателя увеличивается незначительно, особенно учитывая повышенные характеристики автомобиля. Собственно, только калибровкой микропрограммы ECU можно добиться такого сбалансированного прироста производительности и отзывчивости мотора. Поэтому, не стоит пренебрегать возможностью воспользоваться услугой, тем более, никто не задумывается об относительно повышенном износе двигателя при езде в экстремальных условиях, или в самом элементарном случае — при использовании кондиционера.
Но существует единственный нюанс, ни в одной статье не приводится формула или методика подсчета увеличения износа. Стоит заметить, при профессиональном подходе к перепрошивке «мозгов», износ двигателя увеличивается незначительно, особенно учитывая повышенные характеристики автомобиля. Собственно, только калибровкой микропрограммы ECU можно добиться такого сбалансированного прироста производительности и отзывчивости мотора. Поэтому, не стоит пренебрегать возможностью воспользоваться услугой, тем более, никто не задумывается об относительно повышенном износе двигателя при езде в экстремальных условиях, или в самом элементарном случае — при использовании кондиционера.
Каким способом уменьшить негативное влияние чип-тюнинга?
Изменение заводских настроек работы двигателя не означает, что двигатель будет работать в экстремальных условиях. На тех же старых машинах, при установке позднего зажигания считалось, что это приведет к нагару на клапанах и прогоранию поршней.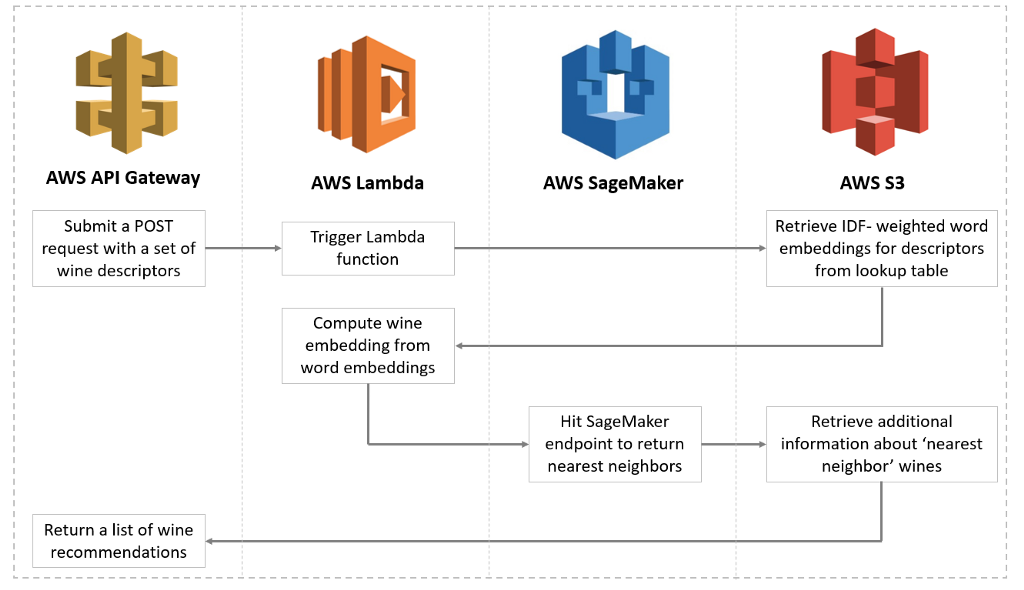 В принципе и такое случалось, но только в случае превышения допустимого регулирования.
В принципе и такое случалось, но только в случае превышения допустимого регулирования.
Это происходило в основном из-за пренебрежения дополнительной регулировки обогащения топливной смеси. Такой подход нивелировал все возможные негативные последствия во вмешательство заводской настройки мотора, при этом получали прирост в динамике машины равный предыдущему методу.
Это приводит к следующим выводам: изменения настроек при чип-тюнинге вредны, а некоторые исключат всю вредность предыдущих изменений. Но стоит отметить, что основной износ двигателя обусловлен в большей степени, манерой езды и временем эксплуатации двигателя, а не тонкой индивидуальной настройкой. Тем более, что существует множество вариантов перенастройки, водители желающие «выжать» все из двигателя, а некоторые хотят улучшить динамику или снизить расход топлива. Желание конечного результата так же влияет на итоговую нагрузку на двигатель.
При перепрошивке управляемой программы атмосферных двигателей для улучшения динамики не всегда приводит к увеличению мощности. В этом случае в основном меняется крутящий момент на определенных оборотах в минуту, это и придает машине прирост в динамике при разгоне и переключении передач.
В этом случае в основном меняется крутящий момент на определенных оборотах в минуту, это и придает машине прирост в динамике при разгоне и переключении передач.
Даже в случае «чиповки» на максимум лошадиных сил можно избежать негативных последствий при грамотном подходе. Профессионалы не один день разрабатывают и тестируют новые прошивки, добиваясь идеального соотношения мощности-износа. Все это зависит от профессионализма мастера и желания клиента. Так к примеру, после грамотного чип тюнинга skoda octavia на http://madcat.biz/chip-tuning/skoda/octavia/ получила в свое распоряжение 225 л.с. хотя по паспорту у нее всего 180 л.с. В этом конкретном случае дополнительной нагрузки на двигатель не произошло вовсе, так как, в заводской программе была сильно занижена мощность из-за экологических норм и для возможности выпустить «заряженную» версию.
Главное преимущество чип-тюнинга перед обычным — это стоимость и удобство. За относительно небольшую плату, Вы приобретете уже самодостаточный тюнинг. При этом не обязательно ориентированный на агрессивный стиль езды. Также, всегда есть возможность вернуть все настройки на заводские. Есть еще один способ использования чип-тюнинга — это сезонный, когда машина перепрошивается под определенный стиль езды в определенный сезон, в этом случае, даже не обязательно каждый раз перепрошивать, а достаточно купить второй блок ECU. Такой способ позволяет самому менять настройки автомобиля в любое удобное время.
При этом не обязательно ориентированный на агрессивный стиль езды. Также, всегда есть возможность вернуть все настройки на заводские. Есть еще один способ использования чип-тюнинга — это сезонный, когда машина перепрошивается под определенный стиль езды в определенный сезон, в этом случае, даже не обязательно каждый раз перепрошивать, а достаточно купить второй блок ECU. Такой способ позволяет самому менять настройки автомобиля в любое удобное время.
Важно о качестве чип-тюнинга
Многие люди ошибочно думают, что существует «оригинальные» и не оригинальные программы для чип-тюнинга. Это глубочайшее заблуждение, так как автопроизводители не признают возможность такого тюнинга, иногда стараются заблокировать возможность перепрошивки блока управления. Также отметим, что перенастройка двигателя не творит чудес, любое улучшение параметров приводит к ухудшению других — износ двигателя, или увеличения вредных выбросов в атмосферу или увеличения расхода топлива, а иногда и повышения требований к топливу. Проблема в том, что на заводе изготовителе, все настройки проведены в компромиссе между всеми факторами, а кустарное «рукоделие» может значительно увеличить негативное влияние перепрошивки.
Проблема в том, что на заводе изготовителе, все настройки проведены в компромиссе между всеми факторами, а кустарное «рукоделие» может значительно увеличить негативное влияние перепрошивки.
Из этого следует, что необходимо обращаться в проверенные временем и опытом тюнинг ателье, а не к дяде Васе из гаражей. Ателье покупают проверенные прошивки у профессионалов, тестировавшие их на стендах и в полевых условиях. И продают уже готовый продукт, Вам не придется постоянно ездить для перепрошивок, когда Вы неожиданно заметите проблемы в работе двигателя. Такое решение может обойтись дороже (разница в цене может отличаться в десятки раз), но избавит от возможных последующих неприятностей.
Предостережение, или в каких случаях делать чип-тюнинг запрещено
Необходимо пояснить важные моменты для желающих «воскресить» старые автомобили. Нельзя заменять ремонт двигателя чип-тюнингом. К примеру, при потере мощности из-за старения двигателя или неисправности датчиков, например: мощность может пропасть из-за слабой компрессии или датчик холостого хода работает в неправильном режиме. Это приведет к ускорению капитального ремонта, а желаемого эффекта можете не получить.
Это приведет к ускорению капитального ремонта, а желаемого эффекта можете не получить.
Новые программы регулирования работы двигателя рассчитаны только на полностью исправные автомобили, в этом случае гарантировано дадут положительный результат.
Главные выводы: чип-тюнинг — это не плохо, но подходить необходимо с полной ответственностью (как и ко всему в жизни). При необдуманных поступках можно сделать хуже. Но прочитав статью и учтя предостережения — Вы вдохнете в автомобиль новую жизнь!
Обзор объяснений модели с участием человека в цикле с помощью Amazon SageMaker Clarify и Amazon A2I
к Викеш Панди и Хасан Пунавала | на | в Amazon Augmented AI, Amazon SageMaker, искусственный интеллект | Постоянная ссылка | Комментарии | Делиться Эксперты домена все чаще используют машинное обучение (ML) для принятия более быстрых решений, которые приводят к лучшим результатам для клиентов в различных отраслях, включая здравоохранение, финансовые услуги и многие другие.
Соблюдение нормативных требований может потребовать от компаний предоставления обоснований решений, принятых в целях ОД. Точно так же внутренние отделы соответствия могут захотеть интерпретировать поведение модели при проверке решений, основанных на прогнозах модели. Например, андеррайтеры хотят понять, почему конкретная заявка на получение кредита была отмечена моделью как подозрительная. Клиенты AWS хотят масштабировать такие интерпретируемые системы с помощью большого количества моделей, поддерживаемых штатом рецензентов.
В этом посте мы используем Amazon SageMaker Clarify для предоставления пояснений к отдельным прогнозам и Amazon Augmented AI (Amazon A2I) для создания рабочего процесса с участием человека и проверки конкретных результатов ниже порогового значения в сценарии использования классификации доходов.
Объяснение индивидуальных прогнозов с помощью проверки человеком может иметь следующие технические проблемы:
- Расширенные алгоритмы машинного обучения изучают нелинейные отношения между входными признаками, а традиционные методы атрибуции признаков, такие как графики частичной зависимости, не могут объяснить вклад каждого признака в каждый отдельный прогноз
- Команды специалистов по обработке и анализу данных должны беспрепятственно переводить объяснения технических моделей бизнес-пользователям для проверки
SageMaker Clarify и Amazon A2I
Clarify предоставляет разработчикам машинного обучения более полную информацию об их данных и моделях, чтобы они могли выявлять возможные отклонения и объяснять прогнозы. SHAP (аддитивные объяснения Шепли), основанный на концепции значения Шепли из области теории кооперативных игр, хорошо работает как для агрегированных, так и для индивидуальных объяснений моделей. Алгоритм Kernel SHAP не зависит от модели, и Clarify использует масштабируемую и эффективную реализацию Kernel SHAP.
Алгоритм Kernel SHAP не зависит от модели, и Clarify использует масштабируемую и эффективную реализацию Kernel SHAP.
Amazon A2I упрощает создание рабочих процессов, необходимых для проверки человеком в нужном масштабе, и избавляет от монотонной тяжелой работы, связанной с созданием систем проверки людьми или управлением большим количеством людей-рецензентов. Вы можете отправлять прогнозы модели и отдельные значения SHAP из Clarify для проверки внутренним командам по обеспечению соблюдения требований и сотрудникам, работающим с клиентами, через Amazon A2I.
Вместе Clarify и Amazon A2I могут завершить цикл от предоставления индивидуальных объяснений до проверки результатов с помощью проверки человеком и получения отзывов для дальнейшего улучшения.
Обзор решения
Мы используем Amazon SageMaker для создания и обучения модели XGBoost, выполняющей классификацию доходов переписи населения в среде Jupyter Notebook. Затем мы используем пакетное преобразование SageMaker для выполнения вывода на пакете тестовых данных и используем Clarify для объяснения отдельных прогнозов в том же пакете. Затем мы настроили Amazon A2I, чтобы создать непосредственную проверку с помощью рабочей силы. Затем мы извлекаем значения SHAP из выходных данных Clarify и запускаем проверку Amazon A2I для прогнозов ниже определенного порога. Мы представляем рецензентам график значений SHAP для каждого экземпляра обзора и позволяем им проверить результат прогноза. Отзывы рецензентов сохраняются в Amazon Simple Storage Service (Amazon S3) и становятся доступными для следующего цикла обучения модели.
Затем мы настроили Amazon A2I, чтобы создать непосредственную проверку с помощью рабочей силы. Затем мы извлекаем значения SHAP из выходных данных Clarify и запускаем проверку Amazon A2I для прогнозов ниже определенного порога. Мы представляем рецензентам график значений SHAP для каждого экземпляра обзора и позволяем им проверить результат прогноза. Отзывы рецензентов сохраняются в Amazon Simple Storage Service (Amazon S3) и становятся доступными для следующего цикла обучения модели.
На следующей диаграмме показана эта архитектура.
Давайте рассмотрим эту архитектуру, чтобы понять детали:
- Обучите модель XGBoost, используя обучающие данные, хранящиеся в Amazon S3. Обученная модель хранится в другой корзине S3.
- По прибытии данных вывода выберите пакет записей и выполните следующие действия:
- Отправьте пакет запросов на вывод в конечную точку.
- Настройте конечную точку пакетного преобразования SageMaker, используя модель, созданную на шаге 1.

- Запустите анализ объяснимости для той же партии с помощью Clarify, чтобы сгенерировать значения SHAP для каждой функции, как в целом, так и для отдельных прогнозов.
- Отфильтруйте отрицательные результаты из результатов прогнозирования и создайте график значений SHAP для этих результатов. Сохраните графики в местоположении Amazon S3, чтобы они были выбраны шаблоном Amazon A2I.
- Создайте цикл проверки человеком с помощью Amazon A2I и укажите результат и график значений SHAP в шаблоне задачи Amazon A2I.
- Рецензенты-люди смотрят на прогноз и значения SHAP, чтобы понять причину отрицательного результата и проверить, принимает ли модель решения без какой-либо предвзятости.
- Соберите все результаты, проверенные людьми, и используйте их в качестве данных, помеченных как достоверные, для целей переобучения.
- Введите следующую партию записей и повторите все подэтапы шага 2.


Размер партии 100 используется только в демонстрационных целях. Мы также можем отправить все данные сразу.
Набор данных
Мы используем набор данных о взрослом населении UCI. Этот набор данных содержит 45 222 строки (32 561 для обучения и 12 661 для тестирования). Каждый экземпляр данных имеет 14 функций, касающихся демографических характеристик людей, таких как лет 9 лет.0067 , рабочий класс , образование , семейное положение , пол и этническая группа . Набор данных предоставляет целевую переменную, показывающую, зарабатывает ли человек больше или меньше 50 000 долларов. Набор данных также предоставляет различные файлы для обучения и тестирования.
Подготовка данных
В рамках предварительной обработки данных мы применяем кодировку метки к целевой переменной, чтобы обозначить 1 как человека, зарабатывающего более 50 000 долларов США и 0 как лицо, зарабатывающее менее 50 000 долларов США. Точно так же такие признаки, как
Точно так же такие признаки, как пол , рабочий класс , образование , семейное положение , отношения и этнический статус кодируются по категориям.
Мы создаем небольшой пакет из 100 записей из обучающих данных, которые мы используем для выполнения пакетного вывода с помощью пакетного преобразования SageMaker, и используем тот же пакет для создания значений SHAP с помощью Clarify. Все эти файлы затем загружаются в Amazon S3.
Модельное обучение
Мы обучаем модель XGBoost, используя встроенный контейнер алгоритма XGBoost, предоставленный SageMaker. SageMaker предоставляет множество встроенных алгоритмов, которые можно использовать для обучения. SageMaker также предоставляет встроенные контейнеры для популярных сред глубокого обучения, таких как TensorFlow, PyTorch и MXNet, а также поддерживает создание собственных контейнеров для обучения и получения выводов.
Вывод
После обучения модели пришло время настроить задание пакетного преобразования для пакетного прогнозирования. Для этого сообщения мы отправляем небольшой пакет записей на конечную точку в зависимости от размера пакета, который мы определили на этапе подготовки данных. В зависимости от варианта использования мы можем соответствующим образом изменить размер партии.
Создание объяснений для прогнозов модели
Запускаем анализ объяснимости с помощью Clarify. Clarify устанавливает эфемерную теневую конечную точку и запускает задание обработки SageMaker для выполнения пакетного вывода на теневой конечной точке для расчета значений SHAP.
Чтобы вычислить значения Шепли, Clarify создает несколько новых экземпляров между базовой линией и заданным экземпляром, в которых отсутствие функции моделируется путем установки значения функции на значение базовой линии, а наличие функции моделируется путем установки значение функции соответствует значению данного экземпляра. Следовательно, отсутствие всех признаков соответствует базовой линии, а наличие всех признаков соответствует данному экземпляру. Clarify вычисляет локальные и глобальные значения SHAP для заданного ввода, который в нашем случае представляет собой пакет записей.
Следовательно, отсутствие всех признаков соответствует базовой линии, а наличие всех признаков соответствует данному экземпляру. Clarify вычисляет локальные и глобальные значения SHAP для заданного ввода, который в нашем случае представляет собой пакет записей.
Результаты объяснимости хранятся в расположении Amazon S3, указанном при настройке задания анализа объяснимости.
Clarify вычисляет глобальные значения SHAP, показывая относительную важность всех объектов в наборе данных, и создает отчеты в форматах HTML, PDF и блокнот. Создается отдельный выходной файл, содержащий значения SHAP для отдельных экземпляров данных. Он также создает файл analysis.json , который содержит глобальные значения SHAP и ожидаемое значение в формате JSON. Мы используем это базовое значение для создания графиков значений SHAP.
Постобработка результатов прогнозов и объяснимости
Затем мы загружаем результаты пакетного преобразования, CSV-файл, содержащий значения SHAP, и файл analysis. json. Имея их локально, мы создаем один кадр данных Pandas, который содержит значения SHAP и соответствующие им прогнозы. Здесь мы преобразуем оценку вероятности каждого прогноза в двоичный вывод на основе порога 0,5. Это устанавливает все прогнозы с оценкой вероятности ниже порогового значения на 0, а прогнозы с оценкой вероятности выше порогового значения на 1. Мы можем изменить порог с 0,5 на любое другое значение от 0 до 1 в соответствии с нашим вариантом использования. Мы ссылаемся на 0 как отрицательный результат и 1 как положительный результат для остальной части поста.
json. Имея их локально, мы создаем один кадр данных Pandas, который содержит значения SHAP и соответствующие им прогнозы. Здесь мы преобразуем оценку вероятности каждого прогноза в двоичный вывод на основе порога 0,5. Это устанавливает все прогнозы с оценкой вероятности ниже порогового значения на 0, а прогнозы с оценкой вероятности выше порогового значения на 1. Мы можем изменить порог с 0,5 на любое другое значение от 0 до 1 в соответствии с нашим вариантом использования. Мы ссылаемся на 0 как отрицательный результат и 1 как положительный результат для остальной части поста.
Следующий код демонстрирует нашу постобработку:
из sagemaker.s3 импорт S3Downloader
импортировать json
# прочитать значения формы
S3Downloader.download(s3_uri=explainability_output_path+"/explanations_shap", local_path="output")
shap_values_df = pd.read_csv("выход/выход.csv")
# прочитать результаты вывода
S3Downloader.download(s3_uri=transformer_s3_output_path, local_path="output")
прогнозы_df = pd. read_csv ("выход/test_features_mini_batch.csv.out", заголовок = нет)
прогнозы_дф = прогнозы_дф.раунд (5)
# получить базовое ожидаемое значение, которое будет использоваться для построения значений SHAP
S3Downloader.download(s3_uri=explainability_output_path+"/analysis.json", local_path="output")
с open('output/analysis.json') как json_file:
данные = json.load(json_file)
base_value = данные ['пояснения']['kernel_shap']['label0']['ожидаемое_значение']
print("базовое значение: ", base_value)
прогнозы_df.columns = ['Оценка_вероятности']
# объединить оценку вероятности и значения формы вместе в одном фрейме данных
предсказание_shap_df = pd.concat ([predictions_df, shap_values_df], ось = 1)
# создайте новый столбец как «Прогноз», преобразуя прогноз в 1 или 0
Prediction_shap_df.insert(0,'Prediction', (prediction_shap_df['Probability_Score'] > 0,5).astype(int))
# добавление столбца индекса на основе размера пакета, который будет использоваться для слияния прогнозов A2I с правдой
Prediction_shap_df['row_num'] = test_features_mini_batch. index
 read_csv ("выход/test_features_mini_batch.csv.out", заголовок = нет)
прогнозы_дф = прогнозы_дф.раунд (5)
# получить базовое ожидаемое значение, которое будет использоваться для построения значений SHAP
S3Downloader.download(s3_uri=explainability_output_path+"/analysis.json", local_path="output")
с open('output/analysis.json') как json_file:
данные = json.load(json_file)
base_value = данные ['пояснения']['kernel_shap']['label0']['ожидаемое_значение']
print("базовое значение: ", base_value)
прогнозы_df.columns = ['Оценка_вероятности']
# объединить оценку вероятности и значения формы вместе в одном фрейме данных
предсказание_shap_df = pd.concat ([predictions_df, shap_values_df], ось = 1)
# создайте новый столбец как «Прогноз», преобразуя прогноз в 1 или 0
Prediction_shap_df.insert(0,'Prediction', (prediction_shap_df['Probability_Score'] > 0,5).astype(int))
# добавление столбца индекса на основе размера пакета, который будет использоваться для слияния прогнозов A2I с правдой
Prediction_shap_df['row_num'] = test_features_mini_batch.
read_csv ("выход/test_features_mini_batch.csv.out", заголовок = нет)
прогнозы_дф = прогнозы_дф.раунд (5)
# получить базовое ожидаемое значение, которое будет использоваться для построения значений SHAP
S3Downloader.download(s3_uri=explainability_output_path+"/analysis.json", local_path="output")
с open('output/analysis.json') как json_file:
данные = json.load(json_file)
base_value = данные ['пояснения']['kernel_shap']['label0']['ожидаемое_значение']
print("базовое значение: ", base_value)
прогнозы_df.columns = ['Оценка_вероятности']
# объединить оценку вероятности и значения формы вместе в одном фрейме данных
предсказание_shap_df = pd.concat ([predictions_df, shap_values_df], ось = 1)
# создайте новый столбец как «Прогноз», преобразуя прогноз в 1 или 0
Prediction_shap_df.insert(0,'Prediction', (prediction_shap_df['Probability_Score'] > 0,5).astype(int))
# добавление столбца индекса на основе размера пакета, который будет использоваться для слияния прогнозов A2I с правдой
Prediction_shap_df['row_num'] = test_features_mini_batch. index
index
Настройка рабочего процесса проверки человеком
Затем мы настроили рабочий процесс проверки вручную с помощью Amazon A2I, чтобы просмотреть все отрицательные результаты, а также их значения SHAP и оценки вероятности. Это повышает прозрачность и доверие ко всему жизненному циклу машинного обучения, поскольку Clarify может предоставить рецензенту полезную информацию, чтобы проверить, не делают ли прогнозы модели в значительной степени зависящими от определенных функций функции, которые способствовали отрицательным результатам, а также достаточно ли высока оценка вероятности. близко к порогу, что делает его отрицательным результатом.
Создайте шаблон рабочей задачи Amazon A2I
Для начала создадим шаблон рабочей задачи с табличными данными. Amazon A2I поддерживает множество шаблонов рабочих задач для вариантов использования, охватывающих изображения, аудио, табличные данные и многое другое. Дополнительные примеры шаблонов рабочих задач см. в репозитории GitHub.
в репозитории GitHub.
Прежде чем продолжить, убедитесь, что у роли SageMaker есть необходимые разрешения для выполнения задач, связанных с Amazon A2I. Дополнительные сведения см. в разделе Предварительные условия для использования дополненного ИИ.
После выполнения всех предварительных условий мы создаем шаблон рабочей задачи. Шаблон имеет следующие столбцы:
- Номер строки (уникальный идентификатор для каждой записи, который будет использоваться позже для подготовки наземных данных для повторного обучения)
- Прогнозируемый результат (0 или 1)
- Оценка вероятности исхода (более высокое значение указывает на более высокую вероятность положительного исхода)
- График значения SHAP для результата (показывающий три основные функции, которые повлияли на прогноз модели)
- Согласен или не согласен с оценкой
- Причина изменения
Создание определения рабочего процесса для Amazon A2I
После создания шаблона нам необходимо создать определение рабочего процесса. Определение рабочего процесса позволяет нам указать следующее:
Определение рабочего процесса позволяет нам указать следующее:
- Рабочая сила, на которую отправляются наши задачи
- Инструкции, которые получает наш персонал (так называемый шаблон рабочей задачи )
- Где хранятся наши выходные данные
Подготовка данных для рабочего процесса проверки человеком
Как мы уже говорили ранее, мы отправляем все отрицательные результаты на проверку людям. Мы фильтруем записи с отрицательным результатом, строим график значений SHAP для этих записей и загружаем их в Amazon S3. Чтобы построить график для значений SHAP, мы используем библиотеку SHAP с открытым исходным кодом. На графике значений SHAP мы показываем только три основные функции, которые в наибольшей степени влияют на результат.
Мы также модифицируем те же Pandas, которые используются во время постобработки, добавляя URI Amazon S3 для каждого загруженного графика для значений SHAP, поскольку нам необходимо указать эти пути в шаблоне рабочей задачи Amazon A2I. См. следующий код:
См. следующий код:
импортная форма
импортировать matplotlib.pyplot как plt
column_list = список (test_features_mini_batch.columns)
s3_uris =[]
для i в диапазоне (len (negative_outcomes_df)):
объяснение_объекта = форма._объяснение.Объяснение(значения=negative_outcomes_df.iloc[i,2:-1].to_numpy(), base_values=base_value, data=test_features_mini_batch.iloc[i].to_numpy(), feature_names=column_list)
shap.plots.waterfall (shap_values = explanation_obj, max_display = 4, show = False)
img_name = 'shap-' + str(i) + '.png'
plt.savefig('shap_images/'+img_name, bbox_inches='tight')
plt.close()
s3_uri = S3Uploader.upload('shap_images/'+img_name, 's3://{}/{}/shap_images'.format(bucket, префикс))
s3_uris.append(s3_uri)
отрицательный_outcomes_df['shap_image_s3_uri'] = s3_uris
Запустить цикл проверки человеком
Теперь у нас есть все необходимое для запуска цикла проверки человеком. Мы отправляем небольшой пакет из трех записей каждому из рецензентов, чтобы они могли проанализировать отдельные прогнозы и сравнить значения SHAP по прогнозам, чтобы понять, смещена ли модель в отношении определенных атрибутов. Эта возможность сравнения значительно повышает прозрачность и доверие к модели, поскольку рецензенты также получают представление об атрибуции функций модели в прогнозах. Они также могут поделиться своими наблюдениями в разделе комментариев в том же пользовательском интерфейсе.
Эта возможность сравнения значительно повышает прозрачность и доверие к модели, поскольку рецензенты также получают представление об атрибуции функций модели в прогнозах. Они также могут поделиться своими наблюдениями в разделе комментариев в том же пользовательском интерфейсе.
Понимание графиков для значений SHAP
На следующем снимке экрана показан пример пользовательского интерфейса задачи, над которым могут работать рецензенты.
На предыдущем изображении рецензент видит три строки, каждая из которых содержит экземпляр отрицательного результата, а также показатель вероятности и график для значений SHAP. На графике значений SHAP функции, повышающие оценку прогноза (вправо), показаны красным цветом, а функции, снижающие прогноз, — синим цветом. Таким образом, красные подталкивают прогноз к положительному результату, а синие — к отрицательному. Функция E[f(x)] — это ожидаемое значение базового уровня SHAP, рассчитанное Clarify, а f(x) — фактическое значение SHAP, полученное моделью для прогноза. Единицы по оси X представляют собой логарифмические единицы шансов, поэтому отрицательные значения указывают на вероятность менее 0,5 (отрицательный результат) того, что человек зарабатывает более 50 000 долларов в год. По оси Y мы видим три основные функции, в наибольшей степени влияющие на результат. Мы также видим некоторые значения серым текстом рядом с именами функций. Это закодированные по меткам значения этих основных функций, предоставленные во время логического вывода.
Единицы по оси X представляют собой логарифмические единицы шансов, поэтому отрицательные значения указывают на вероятность менее 0,5 (отрицательный результат) того, что человек зарабатывает более 50 000 долларов в год. По оси Y мы видим три основные функции, в наибольшей степени влияющие на результат. Мы также видим некоторые значения серым текстом рядом с именами функций. Это закодированные по меткам значения этих основных функций, предоставленные во время логического вывода.
В первом ряду показатель вероятности равен 0,13, что очень мало, а три верхних признака — это Прирост капитала , Отношения и Семейное положение . Значение свойства Прирост капитала равно 0, а значение свойства Отношения равно 1, что указывает на значение свойства Married-AF-spouse , и Семейное положение равно 5, что указывает на значение Жена . Все три функции подталкивают оценку вероятности к положительному результату, но из-за других менее значимых функций, которые в совокупности тянут прогноз к отрицательному результату, модель дает очень низкую оценку вероятности.
Во второй строке показана другая деталь экземпляра отрицательного результата. Показатель вероятности составляет 0,48, что очень близко к пороговому значению (0,5), что указывает на то, что это могло бы быть положительным результатом, если бы какое-либо свойство относилось к положительному результату несколько выше. Опять же, те же три характеристики Прирост капитала , Отношения и Семейное положение больше всего влияют на предсказание модели и подталкивают ее к положительному результату, но недостаточно, чтобы пересечь порог.
Однако в третьей строке показана другая тенденция. Показатель вероятности очень низок, а функция Age имеет самую высокую атрибуцию, но приближает прогноз к отрицательному результату. Прирост капитала занимает второе место и смещает предсказание модели в противоположном направлении с очень хорошим отрывом, но третья функция Секс снова немного оттягивает его назад. В конце концов, модель дает очень низкую оценку вероятности, что указывает на отрицательный результат. При внимательном наблюдении мы можем увидеть, хотя
В конце концов, модель дает очень низкую оценку вероятности, что указывает на отрицательный результат. При внимательном наблюдении мы можем увидеть, хотя Age и Прирост капитала Функции показаны как большие вкладчики на оси X в диапазоне от -7,5 до -5,5. Таким образом, даже когда атрибуции функций выглядят довольно заметными, они все равно влияют на прогноз модели с очень небольшим отрывом (2,5).
Рецензент-человек может тщательно проанализировать каждое из прогнозов и понять тенденции важности признаков для каждого прогноза, а также между прогнозами. Основываясь на своих наблюдениях, они могут решить, следует ли изменить решение, и указать причину изменения в самом шаблоне. Amazon A2I автоматически записывает все ответы и сохраняет их в формате JSON в хранилище Amazon S3.
Подготовка достоверных данных на основе результатов Amazon A2I
Затем мы загружаем данные результатов Amazon A2I и объединяем их с пакетными данными для создания достоверных данных. Для этого поста все отрицательные результаты были рассмотрены рецензентами-людьми, поэтому их можно рассматривать как истину в целях переподготовки.
Для этого поста все отрицательные результаты были рассмотрены рецензентами-людьми, поэтому их можно рассматривать как истину в целях переподготовки.
Полный код, относящийся к этому сообщению в блоге, можно найти в репозитории GitHub.
Очистить
Во избежание дополнительных затрат удалите конечную точку, созданную как часть примера кода.
Заключение
В этом сообщении показано, как мы можем использовать Clarify и Amazon A2I для повышения прозрачности и доверия к жизненному циклу машинного обучения. функция для просмотра прогнозов и их атрибуции SHAP.
В качестве следующего шага протестируйте этот подход с вашим собственным набором данных и вариантом использования, вдохновившись кодом, чтобы сделать решения ML более прозрачными.
Для получения дополнительной информации о Clarify ознакомьтесь с техническим документом Amazon AI «Справедливость и объяснимость».
Об авторе
Викеш Пандей – специалист по машинному обучению, специалист по архитектуре решений в AWS, помогающий клиентам в Скандинавии и в более широком регионе EMEA проектировать и создавать решения машинного обучения. Вне работы Викеш любит пробовать разные кухни и заниматься спортом на открытом воздухе.
Вне работы Викеш любит пробовать разные кухни и заниматься спортом на открытом воздухе.
Хасан Пунавала — специалист по машинному обучению, архитектор решений в AWS, базирующийся в Лондоне, Великобритания. Хасан помогает клиентам разрабатывать и развертывать приложения машинного обучения в рабочей среде на AWS. Он увлечен использованием машинного обучения для решения бизнес-задач в различных отраслях. В свободное время Хасан любит исследовать природу на свежем воздухе и проводить время с друзьями и семьей.
MLPER-03: Проверить справедливость и объяснимость
Обеспечьте справедливость и объяснимость на каждом этапе жизненного цикла машинного обучения. Скомпилируйте список вопросов для рассмотрения на каждом этапе, включая:
Постановка проблемы. Является ли алгоритм этическим решением проблемы?
Управление данными.
Являются ли данные обучения репрезентативными для различных групп? Находятся
есть предубеждения в этикетках или функциях? Нужно ли модифицировать данные, чтобы смягчить предвзятость?Обучение и оценка. Нужно ли включать ограничения справедливости в целевая функция? Необходимо ли изменение количества моделей для обучения для уменьшения систематической ошибки? Была ли модель оценена с использованием соответствующих показателей справедливости?
Развертывание — модель развернута на популяции, для которой она не была обучена или оценивается?
Мониторинг — Существуют ли неравные эффекты для пользователей?
 Являются ли данные обучения репрезентативными для различных групп? Находятся
есть предубеждения в этикетках или функциях? Нужно ли модифицировать данные, чтобы смягчить предвзятость?
Являются ли данные обучения репрезентативными для различных групп? Находятся
есть предубеждения в этикетках или функциях? Нужно ли модифицировать данные, чтобы смягчить предвзятость?Используйте Amazon SageMaker Clarify — Понимание модели характеристики, отлаживать прогнозы и объяснять, как модели машинного обучения делают прогнозы с Уточнение Amazon SageMaker.
Amazon SageMaker
Clarify использует независимый от модели подход к атрибуции признаков, который включает эффективный
внедрение SHAP (Shapley Additive
пояснения). SageMaker Clarify позволяет:Понимание требований соответствия для справедливости и объяснимости.
Определите, являются ли данные обучения смещенными в своих классах или сегментах населения, особо охраняемые группы.
Разработайте стратегию мониторинга систематической ошибки в данных, когда модель производство.
Рассмотрите компромиссы между сложностью модели и объяснимостью и выберите более простые модели, если требуется объяснимость.
 Amazon SageMaker
Clarify использует независимый от модели подход к атрибуции признаков, который включает эффективный
внедрение SHAP (Shapley Additive
пояснения). SageMaker Clarify позволяет:
Amazon SageMaker
Clarify использует независимый от модели подход к атрибуции признаков, который включает эффективный
внедрение SHAP (Shapley Additive
пояснения). SageMaker Clarify позволяет:Документы
Блоги
Объясняемость модели машинного обучения с помощью Amazon SageMaker Clarify и предварительно созданного SKLearn контейнер
Описание моделей Amazon SageMaker Autopilot с помощью SHAP
Видео
Машинное обучение и общество: Предвзятость, справедливость и объяснимость
Как Clarify помогает разработчикам машинного обучения обнаруживать непреднамеренную предвзятость
Интерпретируемость и объяснимость в машинном обучении
Примеры
Справедливость и объяснимость с SageMaker Clarify
Javascript отключен или недоступен в вашем браузере.