Голосовое управление / Хабр
Введение
Алиса, Siri, Маруся – это далеко не весь список проектов в области голосовых помощников. С каждым днем проектов становится больше, а функционал шире и кажется настал тот момент, когда всерьез можно подумать о переводе компьютера на голосовое управление.
В рамках данного цикла статей я разберу создание голосового ассистента, работающего локально на вашем компьютере и имеющего широкий функционал, начиная с “запусти музыку” и заканчивая “создай новый проект в PyCharm”.
Распознавание речи
Такая популярная тема не могла остаться без огромного количества статей, но с появлением API Яндекса и Google большое количество статей начинается и заканчивается так:
import speech_recognition
Это имеет место быть, но у меня натура пытливая, да и опыт в машинном обучении у меня имеется, так почему бы не сделать распознавание самому? Потому что это огромная гора, потратив на подъем на нее кучу времени ты лишь осознаешь, что вершина очень далеко.
“И что не так с import speech_recognition?” спросили меня, когда я вывел первую версию статьи на суд людской.
Конфиденциальность – Яндекс и Google могут упорно заявлять, что наши данные никуда не утекут и не будут нигде использоваться, но готовы ли вы поставить свою карьеру на это их заявление? Вот и система безопасности любой крупной компании тоже не готова, так что при работе с гос. контрактами или при доступе к секретности использование такого решения будет запрещено.
Языки – Давно вы говорили на керекском? Думаю, что вы даже не слышали как звучит этот язык, все потому, что носителей этого языка всего 2 человека в России. А теперь представим, что один из них захочет себе “Джарвиса”. Конечно это крайний случай, но открытые API не всегда справляются с заявленными языками, что говорить о других?
Интернет – Недавно заезжал в прекрасное место около Рязани – птички, да поля бескрайние. Так вдохновляет! Но Алиса не оценила отсутствие интернета.
 Такая любовь к городской жизни объяснима, хоть детище Яндекса и может распознать голос любого человека, говорящего на русском языке, но развернуть такую махину на компьютере (Сбер недавно заявлял о Нейросети на 23 млрд параметров), а тем более на своем смартфоне задача невыполнимая.
Такая любовь к городской жизни объяснима, хоть детище Яндекса и может распознать голос любого человека, говорящего на русском языке, но развернуть такую махину на компьютере (Сбер недавно заявлял о Нейросети на 23 млрд параметров), а тем более на своем смартфоне задача невыполнимая.
 Такая любовь к городской жизни объяснима, хоть детище Яндекса и может распознать голос любого человека, говорящего на русском языке, но развернуть такую махину на компьютере (Сбер недавно заявлял о Нейросети на 23 млрд параметров), а тем более на своем смартфоне задача невыполнимая.
Такая любовь к городской жизни объяснима, хоть детище Яндекса и может распознать голос любого человека, говорящего на русском языке, но развернуть такую махину на компьютере (Сбер недавно заявлял о Нейросети на 23 млрд параметров), а тем более на своем смартфоне задача невыполнимая.Определившись со значимостью, начнем по порядку.
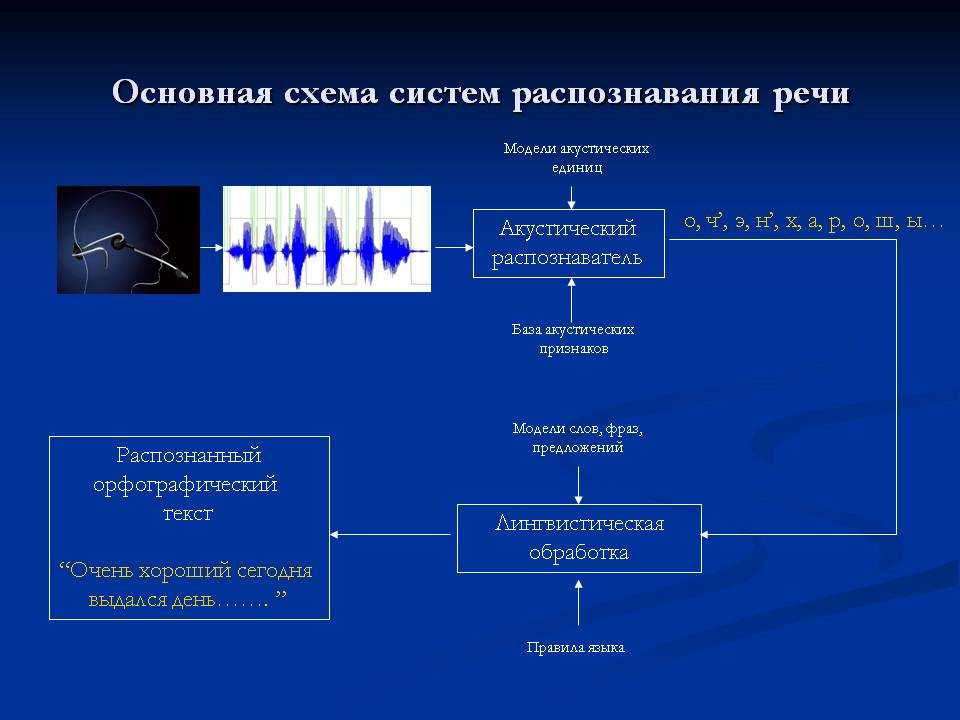
Звук – это волна
Компьютер не дружит с волнами, но обожает цифры.
Возьмем какое-то время t (шаг дискретизации), например 1 секунда. И начнем через каждое время t записывать уровень шума на микрофоне (точки на графике ниже). После чего возьмем число A = 256. Это число будет характеризовать во сколько бит мы хотим записать точку.
– Уровень максимального шума (УМШ) – максимальное значение, которое может выдать микрофон
– Уровень тишины (УТ) – значение, которое выдает микрофон при тишине
Тогда УМШ после записи должен быть равен (А-1), то есть 255, а УТ = 0
Отсюда, число ШК = (УМШ – УТ) / А
ШК – шаг квантования
 ru/referat-obzor-i-analiz-funkcionalenosti-programmnogo-obespeche.html
ru/referat-obzor-i-analiz-funkcionalenosti-programmnogo-obespeche.htmlТеперь каждое t секунд мы будем брать значение с микрофона, делить его на ШК и полученное число записывать в файл. Записанный файл назовем “Запись 1.wav” и попробуем послушать. Ничего осознанного там мы не услышим, так как мы взяли очень большой шаг дискретизации (t). Здесь появляется еще одна характеристика записи – частота дискретизации.
Из физики помним, что:
Возьмем часто используемую частоту 44 кГц, и теперь голос на записи начал звучать. Сохраним запись в папочке Data, чтобы удобнее было с ней работать.
FFT
Мы записали 5 секунд с частотой дискретизации 44 кГц и получили 200 000 чисел. Как можно заставить компьютер понять, что там сказано?
Так как звук это волна, значит, то что мы записали есть сумма колебаний разных частот, а как доказано до меня, именно в частоте скрыта информация передаваемая звуком. Здесь то мы и приходим к преобразованию Фурье (FT), а точнее его модификации Быстрое преобразование Фурье (FFT).
Здесь подробно рассказано, как это работает.
После преобразования Фурье мы получаем набор частот, характеризующий нашу дорожку.
https://proglib.io/p/preobrazovaniya-fure-dlya-obrabotki-signalov-s-pomoshchyu-python-2020-11-03На этом этапе мы можем сделать отсеивание информации. Так как мы слышим в диапазоне от 20 Гц до 20 кГц, все что выше этого диапазона нас не интересует. Мы же используем речь, чтобы общаться друг с другом, а значит кодированная информация должна лежать в слышимом диапазоне.
Мы хотим посимвольно распознавать речь, ведь это даст нам более гибкий инструмент. Для этого используем “окна”. Возьмем первые n наносекунд и сделаем для них преобразование Фурье. Потом следующие n и так далее. Теперь у нас есть данные, основываясь на которых мы можем попробовать предсказать, какой символ из нашего словаря произносится в каждом “окне”.
Также мы не знаем, когда именно сказана буква. Может произойти так, что она попадет на стык “окон”, что разобьет букву на два “окна” и затруднит ее распознавание. Тогда хочется взять “окно” с данными из предыдущего “окна”, тем самым делая нахлест.
Тогда хочется взять “окно” с данными из предыдущего “окна”, тем самым делая нахлест.
Проведя преобразование Фурье для всех “окон”, мы получим спектрограмму .
https://keras.io/examples/audio/ctc_asr/Теперь мы можем работать с ней как с картинкой и применить алгоритмы, помогающие компьютерам видеть собак или объезжать препятствия, но такой подход говорит о том, что нейронная сеть будет просто прогнозировать вероятность соответствия преобразования Фурье символу из словаря. В сказанных словах еще есть иногда и смысл, чтобы его могла использовать наша нейронная сеть используем LSTM слой.
LSTM
Чтобы не расширять статью, здесь не буду рассказывать, что такое нейронная сеть.
Вот на этом канале можно послушать про основы.
Когда мы говорим о нейронных сетях, то возникает такое представление:
Да, это крутая визуализация простой нейросети. Но когда мы хотим работать со смыслом текста, то нам нужен контекст, а следовательно, нейросеть должна помнить, что было до этого. Для такой памяти разработали рекуррентные нейронные сети (RNN).
Для такой памяти разработали рекуррентные нейронные сети (RNN).
RNN слой имеет, как и обычный слой, вход X и выход Y, но при этом еще есть вход h(t-1) и выход h. Когда нейронная сеть такого типа просчитывает себя, она формирует массив Y, который идет не только на выход слоя, но и на вход следующему просчету сети.
Пример:
Хотим перевести “Привет” на английский язык.
Первый проход сети:
x = “п” в категориальном представлении x.shape = (1, 34)
h(t-1) = нулевой вектор h(t-1).shape = (1, 22)
y = w * (h & x), здесь x и h дополняют друг друга (h & x).shape = (1, 56), w.shape = (1, 56)
Второй проход сети:
x = “р” в категориальном представлении x.shape = (1, 34)
h(t-1) = y из прошлого прохода h(t-1).shape = (1, 22)
y = w * (h & x), здесь x и h дополняют друг друга (h & x).shape = (1, 56), w.shape = (1, 56)
Словарь
“В категориальном представлении”, давайте теперь разберемся с тем, что я имел ввиду.
Как с волнами – компьютер, так и машинное обучение с буквами не очень дружит. Следовательно, нам нужно превратить буквы в цифры. Самое простое, что можно придумать, это пронумеровать символы, получив словарь:
{“а”: 0, “б”: 1, “в”: 2, “г”: 3, “д”: 4 … ” “: 37}
В данном режиме на выходе нейронной сети мы будем получать одно число от 0 до 37, которое не будет иметь правильного смысла. Например, если нейронная сеть будет думать между “а” и “я”, то в ответе она вообще выдаст какое-нибудь “п”. Чтобы этого не произошло, давайте попросим нейросеть выдавать нам вероятность того или иного символа на этом месте. Чтобы это реализовать наш словарь должен иметь такой вид:
{
“а”: [1, 0, 0, 0 …],
“б”: [0, 1, 0, 0 …],
“в”: [0, 0, 1, 0 …],
“г”: [0, 0, 0, 1 …]
…
” “: [… 0, 0, 0, 1]
}
Здесь каждый символ закодирован массивом из нулей, где на месте порядкового номера стоит 1. Получив такой словарь, мы можем перейти к подготовке данных для обучения.
Данные
Теперь перейдем к одному из самых интересных вопросов: “Где взять данные?”.
Вообще есть два варианта:
Создать
Скачать
Со “скачать” все просто, например для начального обучения я использовал этот датасет (Habr/Git)
Преобразование данных, с которым я столкнулся в этой статье, принимает на вход WAV файлы, так что преобразуем OPUS в WAV:
import pandas as pd
import soundfile as sf
import os
def convert_opus_to_wav(data):
for index in data.index: # Пробегаем по встроенному манифесту датасета
file = "Data/" + data.loc[index, "Файлы"] # Запоминаем путь к opus файлу
if os.path.exists(file): # Если файл есть, то преобразовываем
audio, sample_rate = sf.read(file, dtype='int16') # Читаем opus
sf.write(file.replace(".opus", ".wav"), audio, sample_rate) # Сохраняем wav
os.remove(file) # Заметаем следы (Удаляем преобразованный файл)
manifest = pd.read_csv("Data/public_series_1. csv", header=None) # Считываем манифест
manifest.columns = ["Файлы", "Текст", "Длительность"] # Чтоб по красоте
del manifest["Длительность"] # Удаляю все что не планирую использовать
convert_opus_to_wav(manifest)
На данный момент обучение проходило на модулях:
asr_public_stories_1 – аудиокниги
public_series_1 – YouTube
public_youtube700_val – YouTube
Также нам надо подправить еще немного манифест и сохранить исправления:
for i in manifest.index:
# Удаляем расширение и добавляем нужную директорию
manifest.loc[i, "Файлы"] = "Data/" + manifest.loc[i, "Файлы"].replace(".wav", "").replace(".opus", "")
# Меняем путь к текстовому файлу на сам текст
with open("Data/" + manifest.loc[i, "Текст"], "r") as file:
manifest.loc[i, "Текст"] = file.read().replace("\n", "")
print(manifest.head())
manifest.to_csv("Data/public_series_1_e.csv") Теперь наш манифест имеет такой вид:
Если внимательно пройтись по данной таблице, то можно найти огрехи по типу “ааа”, “яя”, но они встречаются так редко, что лень искать я даже не смог быстро найти для иллюстрации.
Создать же свой датасет тоже не очень сложно, если вас не интересуют конечно объемы Open STT. Чуть позже я выпущу статью о том, как быстро справился с этой задачей с помощью Telegram и 150 строк кода.
В общих словах вам нужно взять текст, разбить его на фразы, а после озвучить эти фразы, записав 1000 WAV файлов (у меня это получилось примерно 1,5 часа данных). В своих экспериментах я взял для озвучивания “Преступление и наказание”, но в ходе озвучки понял, что там попадаются слова, которые в повседневной жизни не встречаются (Спасибо, Кэп), что немного обесценивает знание контекста, к которому мы стремились выбирая LSTM. Так что, думаю, третьим шагом обучения будут заготовленные команды по типу:
CTC loss
Ну вот мы и дошли к самому главным вопросам:
Как провести обучение без сложной разметки?
Как понять, что “орвлыарлов” не похожа на “Привет, как дела?”, и как оценить степень похожести?
В 2006 году вышла статья Алекса Грейвса «Connectionist temporal classification», которая рассказывает как это можно сделать и доказывает это математикой. Так как математика точная наука и не любит приблизительных пересказов, я оставлю ее за скобками своей статьи.
Так как математика точная наука и не любит приблизительных пересказов, я оставлю ее за скобками своей статьи.
Общий смысл подхода сводится к тому, чтобы подсчитать вероятность каждого символа в каждом “окне”, после чего преобразовать это в строку выбрав более вероятные символы (” ” – тоже символ), а дальше подсчитать расстояние Левенштейна выдав его метрикой похожести.
Модель
def build_model(input_dim, output_dim, rnn_layers=2, rnn_units=32, load=False):
model = Sequential()
model.add(layers.Input((None, input_dim), name="input"))
model.add(layers.Reshape((-1, input_dim), name="expand_dim"))
model.add(LSTM(512, return_sequences=True))
model.add(Dropout(0.4))
for i in range(rnn_layers):
model.add(LSTM(rnn_units, return_sequences=True))
model.add(Dropout(0.4))
model.add(Dense(output_dim + 1, activation='softmax'))
if load:
model.load_weights(dir_+"model/my_model_1.hdf5")
opt = keras.optimizers.Adam(learning_rate=1e-4)
model. compile(optimizer=opt, loss=CTCLoss)
model.summary()
return model
model = build_model(input_dim=fft_length // 2 + 1, output_dim=char_to_num.vocabulary_size(), rnn_units=128, load=True)  compile(optimizer=opt, loss=CTCLoss)
model.summary()
return model
model = build_model(input_dim=fft_length // 2 + 1, output_dim=char_to_num.vocabulary_size(), rnn_units=128, load=True)
compile(optimizer=opt, loss=CTCLoss)
model.summary()
return model
model = build_model(input_dim=fft_length // 2 + 1, output_dim=char_to_num.vocabulary_size(), rnn_units=128, load=True)Результат
Тут не все так однозначно, с одной стороны:
А с другой…
Такой результат я получил при обучении на своем компьютере через 2 дня обучения.
Планы
Тут наткнулся на идею поверх прикрутить лингвистическую модель, которая бы удаляла огрехи по типу отсутствия пробелов между словами.
Также скоро закончу кастомный датасет и отполирую им мелкие дефекты.
Выбрать файлы, на которых нейронка спотыкается, и проанализировать. Есть два варианта:
файл дефектный – решение: удаляем его из датасета, благо Open STT огромный
нейронка мало с ним работала – решение: добавляем его в кастомный датасет
Голосовые функции, голосовая активация, рукописный ввод, ввод с клавиатуры и конфиденциальность
Ваша конфиденциальность очень важна для нас. Поэтому мы предоставляем вам контроль над параметрами конфиденциальности распознавания речи в сети, рукописного ввода и персонализации ввода в Windows. Дополнительные сведения об этих функциях см. в следующих разделах.
Поэтому мы предоставляем вам контроль над параметрами конфиденциальности распознавания речи в сети, рукописного ввода и персонализации ввода в Windows. Дополнительные сведения об этих функциях см. в следующих разделах.
Голосовые функции
Майкрософт предоставляет как функцию распознавания речи на устройстве, так и облачные (в сети) технологии распознавания речи.
Если включить параметр распознавания речи в сети, приложения смогут воспользоваться системой облачного распознавания речи Майкрософт. Кроме того, в Windows 10 параметр распознавания речи в сети позволяет использовать диктовку в Windows.
Включение речи при настройке устройства HoloLens или установке Windows Mixed Reality позволяет использовать голос для выполнения команд, диктовки и взаимодействия с приложениями. Будут включатся параметры распознавания речи на основе устройств и распознавания речи в сети. Если оба параметра включено, а гарнитура включена, устройство всегда будет прослушивать голосовые данные и отправлять голосовые данные в облачные технологии распознавания речи Майкрософт.
При использовании облачных технологий распознавания речи Майкрософт (при включенном параметра “Распознавание речи в сети”, при взаимодействии с устройством HoloLens или при использовании голосового ввода) корпорация Майкрософт собирает и использует записи вашего голоса, чтобы предоставлять эту услугу, преобразовывая произнесенные слова, содержащиеся в голосовых данных, в текст. Корпорация Майкрософт не хранит, не анализирует и не прослушивает записи вашего голоса без вашего разрешения. Дополнительные сведения см. в статье Как корпорация Майкрософт защищает мою конфиденциальность при улучшении технологии распознавания речи?
Функцию распознавания речи на устройстве можно использовать без отправки голосовых данных в корпорацию Майкрософт. Однако облачные технологии распознавания речи Майкрософт более точно распознают речь, чем функция распознавания речи на устройстве. Когда параметр распознавания речи через Интернет выключен, голосовые службы, не использующие облако и работающие только на вашем устройстве, такие как экранный диктор и распознавание речи Windows, по-прежнему будут работать, но Майкрософт не будет собирать никакие голосовые данные.
Однако облачные технологии распознавания речи Майкрософт более точно распознают речь, чем функция распознавания речи на устройстве. Когда параметр распознавания речи через Интернет выключен, голосовые службы, не использующие облако и работающие только на вашем устройстве, такие как экранный диктор и распознавание речи Windows, по-прежнему будут работать, но Майкрософт не будет собирать никакие голосовые данные.
Дополнительные сведения о речевых данных, собираемых при использовании Кортаны, см. в разделе Кортана и конфиденциальность.
Когда мы собираем данные, даже если это делается для улучшения работы вашего устройства, мы стремимся предоставлять вам необходимую информацию, чтобы вы могли принять правильные решения о том, как и когда используются эти данные. Вот что следует сделать для управления параметрами распознавания речи.
Управление распознаванием речи в сети
 org/ItemList”>
org/ItemList”>Выполните одно из следующих действий:
Установите для параметра Распознавание речи в сети значение Вкл. или Откл.
Управление использованием голосовых фрагментов для улучшения распознавания речи в сети в Windows 10
-
Перейдите в меню Пуск > Параметры > Конфиденциальность > Распознавание речи.
-
В разделе Помогите сделать распознавание речи в сети лучше
Примечание: Этот параметр доступен не во всех версиях Windows 10. Если параметр недоступен, голосовые записи не будут использоваться для улучшения распознавания речи. Дополнительные сведения о добавлении голосовых записей см. в статье Как корпорация Майкрософт защищает мою конфиденциальность при совершенствовании технологии распознавания речи?
Если параметр недоступен, голосовые записи не будут использоваться для улучшения распознавания речи. Дополнительные сведения о добавлении голосовых записей см. в статье Как корпорация Майкрософт защищает мою конфиденциальность при совершенствовании технологии распознавания речи?
Управление распознаванием речи на устройстве HoloLens
-
Перейдите в меню Пуск> Параметры > Конфиденциальность > Голосовые функции.
-
В разделе Распознавание речи измените значение параметра на Вкл. или Выкл.
Управление распознаванием речи для смешанной реальности
 org/ItemList”>
org/ItemList”>Перейдите в меню Пуск> Параметры > Смешанная реальность > Звук и речь.
В разделе Распознавание речи измените значение параметра Использовать распознавание речи.
Голосовой ввод
В Windows 11 функция диктовки обновлена и переименована: теперь она называется “голосовой ввод”. Функция голосового ввода, как и функция диктовки, использует технологии распознавания речи в сети для преобразования речи в текст. Для использования голосового ввода больше не нужно включать параметр распознавания речи в сети. Также вы можете отправлять голосовые фрагменты, чтобы помочь нам улучшить работу функции голосового ввода. Если вы не хотите оправлять голосовые фрагменты, вы все равно можете пользоваться голосовым вводом. Это можно настроить в любое время в параметрах голосового ввода. Корпорация Майкрософт не хранит, не анализирует и не прослушивает записи вашего голоса без вашего разрешения. Дополнительные сведения см. в статье Дополнительные сведения о Майкрософт и ваших голосовых данных.
Если вы не хотите оправлять голосовые фрагменты, вы все равно можете пользоваться голосовым вводом. Это можно настроить в любое время в параметрах голосового ввода. Корпорация Майкрософт не хранит, не анализирует и не прослушивает записи вашего голоса без вашего разрешения. Дополнительные сведения см. в статье Дополнительные сведения о Майкрософт и ваших голосовых данных.
Начало использования голосового ввода
-
Нажмите клавиши Windows + H или нажмите кнопку микрофона на сенсорной клавиатуре.
-
Нажмите кнопку микрофона .
Управление использованием голосовых фрагментов, записываемых при голосовом вводе, для улучшения распознавания речи в сети в Windows 11
Если вы используете аппаратную клавиатуру
 org/ItemList”>
org/ItemList”>Откройте голосовой ввод, нажав клавиши Windows + H.
Выберите Параметры , затем выполните одно из следующих действий:
-
Чтобы начать отправлять голосовые фрагменты, выберите Узнайте, как начать отправку голосовых фрагментов
-
Чтобы прекратить отправку голосовых фрагментов, выберите Узнайте, как прекратить отправку голосовых фрагментов
Если вы используете сенсорную клавиатуру
 org/ItemList”>
org/ItemList”>Откройте голосовой ввод, нажав кнопку микрофона сенсорной клавиатуре.
Выберите Параметры , затем выполните одно из следующих действий:
-
Чтобы начать отправлять голосовые фрагменты, выберите Помогите нам улучшить голосовой ввод, затем выберите Узнайте, как начать отправку голосовых фрагментов.
-
Чтобы прекратить отправлять голосовые фрагменты, выберите Вы отправляете голосовые фрагменты, затем выберите Узнайте, как начать прекратить голосовых фрагментов.

Примечание: Если вы используете рабочую или учебную учетную запись, отправка голосовых данных недоступна, но вы по-прежнему можете использовать голосовой ввод.
Голосовая активация
Windows предоставляет поддерживаемые приложения, которые могут отвечать и выполнять действия на основе голосовых ключевых слов, настроенных для этого приложения. Например, Кортана может слушать речь и отвечать на фразу «Кортана!».
Если вы предоставите приложению разрешение прослушивать голосовые ключевые слова, Windows будет активно прослушивать микрофон на предмет произнесения этих ключевых слов. При распознавании ключевого слова приложение получит доступ к вашим голосовым записям, сможет обрабатывать эти записи, совершать действия и отвечать (например, используя устные ответы). Приложение сможет отправлять голосовые записи в свои собственные службы, находящиеся в облаке, для обработки команд. Каждое приложение должно запрашивать у вас разрешение на доступ к микрофону. Приложение-помощник может отправлять голосовые записи в свои службы и собирать записи для других целей, например для улучшения служб. Дополнительные сведения см. в заявлении о конфиденциальности для приложения-помощника. Майкрософт не собирает голосовые записи в интересах любых приложений сторонних производителей, для которых вы разрешили голосовую активацию.
Каждое приложение должно запрашивать у вас разрешение на доступ к микрофону. Приложение-помощник может отправлять голосовые записи в свои службы и собирать записи для других целей, например для улучшения служб. Дополнительные сведения см. в заявлении о конфиденциальности для приложения-помощника. Майкрософт не собирает голосовые записи в интересах любых приложений сторонних производителей, для которых вы разрешили голосовую активацию.
Когда голосовой помощник приложения будет готов к активации с помощью произнесенного ключевого слова, на панели задач появится значок микрофона. В Windows 11 он выглядит следующим образом:
Когда голосовой помощник приложения будет активирован и начнет активное прослушивание, чтобы предоставить ответ, сведения на панели задач изменятся. Панель задач будет выглядеть, как на следующем снимке экрана Windows 11 (в данном случае показано, что активирована Кортана):
Голосовую активацию также можно включить, если устройство заблокировано и экран выключен. После того как приложение будет активировано с помощью произнесенного ключевого слова, оно сможет продолжать слушать микрофон. Даже когда устройство заблокировано и экран выключен, приложение может активироваться для всех, кто говорит рядом с устройством и имеет доступ к тому же набору возможностей и информации, что и при разблокировке устройства.
После того как приложение будет активировано с помощью произнесенного ключевого слова, оно сможет продолжать слушать микрофон. Даже когда устройство заблокировано и экран выключен, приложение может активироваться для всех, кто говорит рядом с устройством и имеет доступ к тому же набору возможностей и информации, что и при разблокировке устройства.
Голосовые программы будут работать по-разному в зависимости от параметров спящего режима, которые вы выбрали для устройства, или типа устройства, которое вы используете.
Если вы используете ноутбук или планшет
|
Параметры спящего режима |
Доступность голосовой активации |
Поведение голосового помощника |
|
Переход в спящий режим по истечении определенного периода времени |
Когда экран включен (по умолчанию) |
Голосовой помощник не отвечает после перехода устройства в спящий режим |
|
Никогда не переходить в спящий режим |
Когда устройство подключено к сети |
Голосовая связь будет отвечать только всегда, когда устройство подключено к сети |
Если вы используете моноблок
|
Параметры спящего режима |
Доступность голосовой активации |
Поведение голосового помощника |
|
Переход в спящий режим по истечении определенного периода времени |
Когда экран включен |
Голосовой помощник не сможет ответить после перехода устройства в спящий режим |
|
Никогда не переходить в спящий режим |
Когда устройство подключено к сети (по умолчанию) |
Голосовая связь будет отвечать только всегда, когда устройство подключено к сети |
Из описанного выше поведения есть несколько исключений:
-
Если вы используете ноутбук или планшет с встроенным виртуальным помощником, который поддерживает аппаратное обнаружение ключевых слов, например Алексу или Кортану, голосовой помощник всегда будет отвечать и даже выводить устройство из спящего режима, когда оно работает от батареи.
 org/ListItem”>
org/ListItem”>
Если вы используете ноутбук или планшет, и устройство находится в режиме экономии заряда, голосовой помощник не сможет ответить.
Примечания:
-
Чтобы просмотреть и изменить параметры спящего режима, выполните одно из следующих действий:
-
Чтобы просмотреть и изменить параметры голосовой активации, выполните одно из следующих действий:
-
В Windows 10 перейдите в раздел Пуск > Параметры > конфиденциальность и проверьте различные параметры на страницах Разрешения приложения.
-
В Windows 11 перейдите в раздел Пуск > Параметры > конфиденциальность & безопасность и проверьте различные параметры на страницах Разрешения приложения.
 org/ListItem”>
org/ListItem”>
Чтобы узнать, какие разрешения предоставлены приложению, которое будет доступно при заблокированном устройстве, выполните одно из следующих действий:
Изменение возможности активации приложений, указанных на этой странице параметров, с помощью голосового ключевого слова
Перейдите в меню Пуск > Параметры > Конфиденциальность > Голосовая активация.
Измените параметр Разрешить приложениям использовать голосовую активацию на Вкл. или Выкл..
Изменение возможности использования голосовой активации приложений, указанных на этой странице параметров, когда устройство заблокировано
-
Перейдите в меню Пуск > Параметры > Конфиденциальность > Голосовая активация.
 org/ListItem”>
org/ListItem”>
Измените параметр Разрешить приложениям использовать голосовую активацию , когда это устройство заблокировано на Вкл. или Выкл..
Изменение возможности активации отдельного приложения с помощью голосового ключевого слова
-
Перейдите в меню Пуск > Параметры > Конфиденциальность > Голосовая активация.
-
Включите или отключите каждое приложение в разделе Выберите приложения, которые могут использовать голосовую активацию. Если параметр Разрешить приложениям использовать голосовую активациюотключен для вашей учетной записи пользователя, нужно будет включить его, чтобы можно было включить или отключить этот параметр.
-
В разделе Выберите приложения, которые могут использовать голосовую активацию выберите приложение и измените значение параметра, который позволяет приложению реагировать на ключевые слова, на Выкл.

Изменение возможности отдельного приложения использовать голосовую активацию, если устройство заблокировано
-
Перейдите в меню Пуск > Параметры > Конфиденциальность > Голосовая активация.
-
Включите или отключите каждое приложение в разделе Выберите приложения, которые могут использоватьголосовую активацию.
Если параметр Разрешить приложениям использовать голосовую активацию, когда это устройство заблокированоотключен для вашей учетной записи пользователя, нужно будет включить его, чтобы можно было включить или отключить этот параметр.
 Если параметр Разрешить приложениям использовать голосовую активацию, когда это устройство заблокированоотключен для вашей учетной записи пользователя, нужно будет включить его, чтобы можно было включить или отключить этот параметр.
Если параметр Разрешить приложениям использовать голосовую активацию, когда это устройство заблокированоотключен для вашей учетной записи пользователя, нужно будет включить его, чтобы можно было включить или отключить этот параметр. Изменение возможности активации приложений, указанных на этой странице параметров, с помощью голосового ключевого слова
-
Перейдите в меню Пуск > Параметры > Конфиденциальность и безопасность > Голосовая активация.
-
Установите для параметра Разрешить приложениям доступ к службам голосовой активации значение Вкл.
или Откл.
 или Откл.
или Откл.Изменение возможности использования голосовой активации приложений, указанных на этой странице параметров, когда устройство заблокировано
-
Перейдите в меню Пуск > Параметры > Конфиденциальность и безопасность > Голосовая активация.
-
Разверните параметр Разрешить приложениям доступ к службам голосовой активации.
-
Установите для параметра Разрешить приложениям использовать голосовую активацию, когда устройство заблокировано значение Вкл.
или Откл. Если параметр Разрешить приложениям доступ к службам голосовой активацииотключен, нужно будет включить его, чтобы можно быть включить или отключить этот параметр.
 или Откл. Если параметр Разрешить приложениям доступ к службам голосовой активацииотключен, нужно будет включить его, чтобы можно быть включить или отключить этот параметр.
или Откл. Если параметр Разрешить приложениям доступ к службам голосовой активацииотключен, нужно будет включить его, чтобы можно быть включить или отключить этот параметр. Изменение возможности активации отдельного приложения с помощью голосового ключевого слова
-
Перейдите в меню Пуск > Параметры > Конфиденциальность и безопасность > Голосовая активация.
-
Включите или отключите каждое приложение в разделе Приложения, запросившие доступ к голосовой активации. Если параметр Разрешить приложениям доступ к службам голосовой активацииотключен для вашей учетной записи пользователя, нужно будет включить его, чтобы можно было включить или отключить этот параметр.
-
В разделе Приложения, запросившие доступ к голосовой активации выберите приложение и установите для параметра, разрешающего приложению отвечать на ключевые слова, значение Вкл. или Откл.
Изменение возможности отдельного приложения использовать голосовую активацию, когда устройство заблокировано
-
Перейдите в меню Пуск > Параметры > Конфиденциальность и безопасность > Голосовая активация.
-
Разверните приложение в разделе Приложения, запросившие доступ к голосовой активации.
-
Установите или снимите флажок Использовать, даже если устройство заблокировано для этого приложения. Этот параметр должен быть включен для этого приложения, чтобы можно было установить или снять этот флажок.

Персонализация рукописного ввода и ввода
В рамках рукописного ввода и ввода на устройстве Windows собирает уникальные слова( например, имена, которые вы пишете) в пользовательском списке слов, сохраненном в вашей учетной записи, что помогает более точно вводить и рукописный ввод. Этот список слов доступен вам в других продуктах Майкрософт при входе.
Отключение рукописного ввода и персонализации ввода и очистка настраиваемого списка слов
-
В Windows 11 перейдите в раздел Пуск > Параметры > Конфиденциальность & безопасности > рукописный ввод & ввода персонализации и переключите параметр Настраиваемое рукописное ввод и ввод списка слов в значение Выкл.
 org/ListItem”>
org/ListItem”>
В Windows 10 перейдите в меню Пуск > Параметры > Конфиденциальность > Персонализация рукописного ввода и ввода с клавиатуры, затем в разделе Наше знакомство переключите параметр в положение Откл.
Используйте голосовое управление для взаимодействия с iPhone
Вы можете управлять iPhone только с помощью голоса. Произносите команды для выполнения жестов, взаимодействия с элементами экрана, диктовки и редактирования текста и многого другого.
Настройка голосового управления
Перед первым включением голосового управления убедитесь, что iPhone подключен к Интернету через сеть Wi-Fi. После того как iPhone завершит однократную загрузку файла с сайта Apple, вам не потребуется подключение к Интернету для использования голосового управления.
Выберите «Настройки» > «Универсальный доступ» > «Голосовое управление».
Нажмите «Настроить голосовое управление», затем нажмите «Продолжить», чтобы начать загрузку файла.
Когда загрузка будет завершена, в строке состояния появится значок, указывающий на то, что голосовое управление включено.
Установите следующие параметры:
Язык: Установите язык и загрузите языки для автономного использования.
Команды настройки: Просмотрите доступные команды и создайте новые команды.
Словарный запас: Научите голосовое управление новым словам.
Показать подтверждение: Когда голосовое управление распознает команду, в верхней части экрана появляется визуальное подтверждение.
Звук воспроизведения: Когда голосовое управление распознает команду, воспроизводится звуковой сигнал.
Показать подсказки: Посмотреть подсказки и подсказки по командам.
Наложение: Отображать числа, имена или сетку поверх элементов экрана.
Внимание: На iPhone с Face ID функция «Голосовое управление» активируется, когда вы смотрите на iPhone, и засыпает, когда вы отводите взгляд.

Включение и выключение голосового управления
После настройки голосового управления его можно быстро включить или отключить одним из следующих способов:
Активируйте Siri и произнесите «Включить голосовое управление» ».
Скажите «Отключить голосовое управление».
Добавление голосового управления к ярлыкам специальных возможностей — выберите «Настройки» > «Универсальный доступ» > «Ярлык специальных возможностей», затем коснитесь «Голосовое управление».

Изучение команд голосового управления
Когда голосовое управление включено, вы можете произносить такие команды, как следующие:
Чтобы узнать больше о голосовых командах, скажите «Покажи, что сказать» или «Покажи команды».
Использовать наложение экрана
Для более быстрого взаимодействия вы можете перемещаться по iPhone с помощью наложения экрана, на котором отображаются названия элементов, числа или сетка.
Названия элементов: Произнесите «Показывать имена» или «Показывать имена непрерывно», затем скажите «Нажмите имя элемента ».
Числа: Произнесите «Показывать числа» или «Показывать числа непрерывно», затем произнесите число рядом с нужным элементом.
Также можно дать команду на выполнение жеста, например «Нажмите номер », «Длительное нажатие , номер », «Проведите пальцем вверх по номеру , номер », или «Дважды нажмите , номер ».Сетка: Чтобы взаимодействовать с местом на экране, не представленным именем или номером элемента, скажите «Показать сетку» или «Показывать сетку непрерывно», затем выполните любое из следующих действий:
Разверните: Произнесите число, чтобы отобразить более подробную сетку.
Произнесите команду для взаимодействия с областью сетки: Произнесите что-то вроде: «Нажмите номер » или «Увеличить номер ».
Совет: Чтобы настроить количество строк и столбцов сетки, выберите «Настройки» > «Универсальный доступ» > «Голосовое управление» > «Наложение», затем выберите «Пронумерованная сетка». Когда голосовое управление включено, вы также можете сказать, например, «Показать сетку с пятью строками» или «Показать сетку непрерывно с тремя столбцами».
 Также можно дать команду на выполнение жеста, например «Нажмите номер », «Длительное нажатие , номер », «Проведите пальцем вверх по номеру , номер », или «Дважды нажмите , номер ».
Также можно дать команду на выполнение жеста, например «Нажмите номер », «Длительное нажатие , номер », «Проведите пальцем вверх по номеру , номер », или «Дважды нажмите , номер ».
Чтобы отключить наложение, произнесите «Скрыть имена», «Скрыть числа» или «Скрыть сетку».
Переключение между режимом диктовки, режимом правописания и командным режимом
Когда вы работаете в области ввода текста, например, пишете документ, электронное письмо или сообщение, вы можете легко переключаться между режимом диктовки, режимом правописания и командным режимом по мере необходимости. В режиме диктовки (по умолчанию) любые произносимые вами слова, не являющиеся командами голосового управления, вводятся как текст. В командном режиме эти слова игнорируются и не вводятся как текст; Голосовое управление реагирует только на команды. Командный режим особенно полезен, когда вам нужно использовать ряд команд и вы хотите предотвратить непреднамеренный ввод того, что вы говорите, в область ввода текста.
Когда вы находитесь в режиме диктовки и вам нужно произнести слово по буквам, произнесите «Режим правописания». Чтобы вернуться в режим диктовки, произнесите «Режим диктовки».
Чтобы вернуться в режим диктовки, произнесите «Режим диктовки».
Чтобы переключиться в командный режим, произнесите «Командный режим». Когда режим команд включен, в области ввода текста появляется темный значок перечеркнутого символа, указывающий на то, что вы не можете диктовать. Чтобы вернуться в режим диктовки, произнесите «Режим диктовки».
объектив c — Голосовое управление без нажатия кнопки на iOS
Задавать вопрос
спросил
Изменено 1 месяц назад
Просмотрено 3к раз
В настоящее время я работаю над разработкой приложения для iOS, которое запускает событие по голосовой команде.
Я видел приложение камеры, где пользователь говорит “начать запись”, после чего камера переходит в режим записи.
Это возможность голосового управления в приложении, поэтому я думаю, что она отличается от SiriKit или SpeechRecognizer, которые я уже реализовал.
Как мне этого добиться?
Мой вопрос НЕ касается голосовой диктовки, когда пользователь должен нажать кнопку, чтобы начать диктовку.
Приложение должно пассивно ожидать ключевого слова или намерения, например «myApp, начать запись» или «myApp, остановить запись», после чего приложение запускает/останавливает эту функцию события соответственно.
Спасибо.
- ios
- объектив-с
- распознавание голоса
- голосовое управление
1
OpenEars : свободное распознавание речи и синтез речи для iPhone.
OpenEars позволяет быстро и легко добавить офлайн-распознавание речи на многих языках и синтезированную речь/TTS в приложение для iPhone. Это позволяет каждому получить отличные результаты от использования расширенных концепций интерфейса голосового приложения. Проверьте эту ссылку.
http://www.politepix.com/openears/
или
Проверьте эту ссылку.
http://www.politepix.com/openears/
или
Создание iOS-приложения, такого как Siri https://www.raywenderlich.com/60870/building-ios-app-like-siri
Спасибо.
5
Как мне этого добиться?
Существует iOS 13 новая функция под названием Голосовое управление , которая позволит вам достичь своей цели.
Полезную информацию можно найти в разделе Настройка команд , где доступны все голосовые команды (вы также можете создать собственный) :
На примере упомянутой вами камеры все можно сделать вокально следующим образом: Я показал имена элементов, чтобы понять голосовые команды, которые я использовал, но их можно скрыть, если вы предпочитаете ( скрыть имена ) .
Голосовое управление — это встроенная функция , которую вы также можете использовать в своих приложениях.